

最近の生成AIの勢いはすごいですね。
GTP-NextだのOrionだのGPT4o-1だの言われているらしいですが、50代のおじさん(私)はついていくのが大変です。
というわけで、入門的にRAGに挑戦してみました。
LangChainのサンプルをやってみようと思ったんですが、いろいろ壁にぶつかって結果的に全くの別物になってしまいましたが一応サンプルと同じ構成のRAGを作成できたので皆さんに共有したいと思います。
今回の内容
LangChainのサンプルは、Pythonソースをエンベディングして、その内容をもとに回答するようなチャットするもののようです。
このサンプルではエンベディングとLLMをOpenAIで実装していますが、お金をかけたくないのでVectoreStore(DB)はもちろん、エンベディングとLLMについてもローカル実行としています。
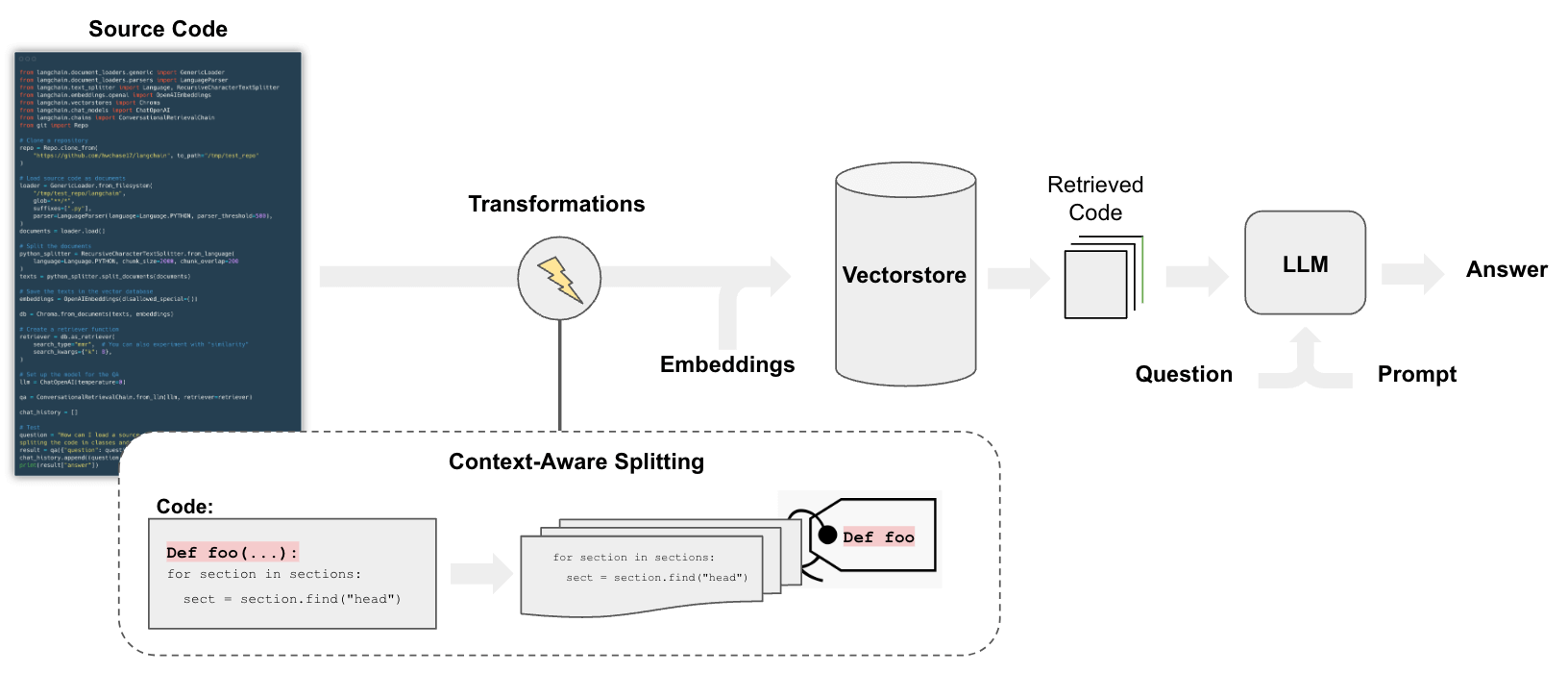
サンプルの構成は上記の絵の通りで、サンプルPythonソースをエンベディングしてVectorDBに入れてLLMのナレッジとするRAGを構築します。
最終的に参照するソースに対して
(英語で)Runnable クラスのクラス階層に関連して、コードでどのような改善を提案しますか?
という質問をして
(もちろん英語で)考えられる機能強化の 1 つは、構成データを保存する runnable_config 属性を追加し、実行可能ファイル自体からそれを変更するための APIを提供することです
みたいな返事をしてもらうようになるみたいです。
エンベディングとLLMについては、HuggingFaceのものをダウンロードして使用します。
前提
今回は、Windows10上のwsl2のLinuxで作成します。
ホストPCのスペックは以下の通り。ごく一般的なノートPCです。GPUのAIでの利用は行っていません。
OS 名: Microsoft Windows 10 Pro
プロセッサ: Intel64 Family 6 Model 154 Stepping 4 GenuineIntel ~1300 Mhz
物理メモリの合計: 16,016 MB
ゲストOSはUbuntu24.04を使用します。(Ubuntu20.04を使ったらライブラリのインストールでLibcとかのエラーが出たので24.04を使用しています)
Pythonは3.12(プレインストール)を使用します。
今回はPythonインタープリターを使って実行します。
ふつうは、Jupyter NotebookとかAnacondaとかGoogle Colabとか使うと思いますが面倒なので。
ユーザは切り替えるのが面倒(wsl2のオプション付けるだけなんだけど)なのでrootでやっちゃってます。
以降、LangChainサンプルにある手順については、[LangChainサンプルの手順]と記載しています。記載がないものは独自の手順です。
1. 環境準備
ライブラリをごちゃごちゃ入れるので一応venvを使用します。
プレインストールには無いのでvenvとpipをインストールします。
add-apt-repository ppa:deadsnakes/ppa
apt -y update
apt -y upgrade
apt -y install python3.12-venv python3-pip
作業用のフォルダを作成してvenvを作成、切り替えます。
cd
mkdir langchain-sample
cd langchain-sample/
python3 -m venv venv
venvを開始します。(終了は、deactivate)
venv/bin/activate
必要なライブラリをインストールします。[LangChainサンプルの手順]
pip install --upgrade --quiet langchain-openai tiktoken langchain-chroma langchain GitPython
ライブラリが足りないので以下もインストール。
pip install langchain-community langchain-core
2.RAG構築
Pythonインタープリタを起動します。
python
インポートします。[LangChainサンプルの手順]
>>> from git import Repo
>>> from langchain_community.document_loaders.generic import GenericLoader
>>> from langchain_community.document_loaders.parsers import LanguageParser
>>> from langchain_text_splitters import Language
Gitからサンプルソースをクローンします。[LangChainサンプルの手順]
>>> repo_path = "/Users/jacoblee/Desktop/test_repo"
>>> repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)

ソース(.pyファイル)をロードします。[LangChainサンプルの手順]
最後にドキュメント数を表示しています。(ファイルは)
>>> loader = GenericLoader.from_filesystem(
repo_path + "/libs/core/langchain_core",
glob="**/*",
suffixes=[".py"],
exclude=["**/non-utf8-encoding.py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
>>> documents = loader.load()
>>> len(documents)
447
埋め込みとベクトル保存のために、テキストスプリッターでチャンクに分割します。[LangChainサンプルの手順]
最後に分割した数を表示しています。
>>> from langchain_text_splitters import RecursiveCharacterTextSplitter
>>> python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=2000, chunk_overlap=200
)
>>> texts = python_splitter.split_documents(documents)
>>> len(texts)
1359
埋め込みとドキュメントをベクター ストアに保存します。
GitHubサイトの手順ではOpenAIのエンベディングを使用することになってますが、私のアカウントの無料期間が終わってしまっているので、今回はHuggingFaceのエンベディングをローカル実行で利用します。
>>> from langchain_chroma import Chroma
>>> from huggingface_hub import snapshot_download
>>> model_name = "intfloat/multilingual-e5-base"
>>> model_path = f"path_to_model/{model_name}"
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_path)
>>> db = Chroma.from_documents(texts, embeddings) # ←DB登録、10分ぐらいかかる
>>> retriever = db.as_retriever(
search_type="mmr", # Also test "similarity"
search_kwargs={"k": 8},
)
ChromaDBはデフォルトでSqlite3を使っているようですね。DB名はデフォルトで”DB”となるようです。
カレントディレクトリに”DB”というディレクトリができてSqlite3のファイルができています。
サンプルソースのファイルが大体200MBで、出来上がったDBサイズが154KB、意外とコンパクトになるみたいです。

3.チャットテスト
ここもGitHubサイトではOpenAIを使ってますが、HuggingFaceから取得したLLMをローカル実行で代替えします。
若干ライブラリが足りないので追加します。
※別コンソールで実行
pip install -qU langchain-community llama-cpp-python
LLMをダウンロードします。
wget https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/blob/main/llama-2-7b-chat.ggmlv3.q4_0.bin
>>> import multiprocessing
>>> from langchain_community.chat_models import ChatLlamaCpp
>>> from langchain.chains import create_history_aware_retriever, create_retrieval_chain
>>> from langchain.chains.combine_documents import create_stuff_documents_chain
>>> from langchain_core.prompts import ChatPromptTemplate
>>> local_model = "./ELYZA-japanese-Llama-2-7b-instruct-q4_K_M.gguf"
>>> llm = ChatLlamaCpp(
temperature=0.5,
model_path=local_model,
n_ctx=10000,
n_gpu_layers=8,
n_batch=300, # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
max_tokens=512,
n_threads=multiprocessing.cpu_count() - 1,
repeat_penalty=1.5,
top_p=0.5,
verbose=True,
)
llama_model_loader: loaded meta data with 21 key-value pairs and 291 tensors from ./ELYZA-japanese-Llama-2-7b-instruct-q4_K_M.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = ELYZA-japanese-Llama-2-7b-instruct
...
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 1
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
Model metadata: {'general.file_type': '15', 'tokenizer.ggml.unknown_token_id': '0', 'tokenizer.ggml.eos_token_id': '2', 'general.architecture': 'llama', 'llama.context_length': '4096', 'general.name': 'ELYZA-japanese-Llama-2-7b-instruct', 'general.source.hugginface.repository': 'elyza/ELYZA-japanese-Llama-2-7b-instruct', 'llama.embedding_length': '4096', 'llama.tensor_data_layout': 'Meta AI original pth', 'llama.feed_forward_length': '11008', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'llama.rope.dimension_count': '128', 'tokenizer.ggml.bos_token_id': '1', 'llama.attention.head_count': '32', 'llama.block_count': '32', 'llama.attention.head_count_kv': '32', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'llama'}
Using fallback chat format: llama-2
>>> prompt = ChatPromptTemplate.from_messages(
[
("placeholder", "{chat_history}"),
("user", "{input}"),
(
"user",
"Given the above conversation, generate a search query to look up to get information relevant to the conversation",
),
]
)
>>> retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
>>> prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
("placeholder", "{chat_history}"),
("user", "{input}"),
]
)
プロンプト(クエリ)を作ります。[LangChainサンプルの手順]
>>> document_chain = create_stuff_documents_chain(llm, prompt)
>>> qa = create_retrieval_chain(retriever_chain, document_chain)
>>> questions = [
"What classes are derived from the Runnable class?",
"What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?",
]
いよいよ、クエリを投げます![LangChainサンプルの手順]
>>> for question in questions:
result = qa.invoke({"input": question})
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
さすがローカル実行、めちゃ時間かかります。
CPUもめちゃめちゃ熱を持つので扇風機で冷やしながら、そっとしておきましょう。
10分ぐらい待つと以下のような結果が返ってきました。
llama_print_timings: load time = 18287.04 ms
llama_print_timings: sample time = 19.53 ms / 41 runs ( 0.48 ms per token, 2099.44 tokens per second)
llama_print_timings: prompt eval time = 239301.92 ms / 3033 tokens ( 78.90 ms per token, 12.67 tokens per second)
llama_print_timings: eval time = 93045.05 ms / 40 runs ( 2326.13 ms per token, 0.43 tokens per second)
llama_print_timings: total time = 332737.48 ms / 3073 tokens
-> **Question**: What classes are derived from the Runnable class?
**Answer**: The following classes derive directly or indirectly (via inheritance) from `Runnable`: Unterscheidung: HP ProLiant DL360 G5 vs IBM xSeries...`.
Llama.generate: 23 prefix-match hit, remaining 3001 prompt tokens to eval
llama_print_timings: load time = 18287.04 ms
llama_print_timings: sample time = 22.67 ms / 44 runs ( 0.52 ms per token, 1940.63 tokens per second)
llama_print_timings: prompt eval time = 222086.44 ms / 3000 tokens ( 74.03 ms per token, 13.51 tokens per second)
llama_print_timings: eval time = 110746.84 ms / 44 runs ( 2516.97 ms per token, 0.40 tokens per second)
llama_print_timings: total time = 333207.12 ms / 3044 tokens
-> **Question**: What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?
**Answer**: One potential improvement is adding a `runnable_support` function that provides an overload with default parameter values, making it easier and more consistent across LangChain.
```python hopefully this helps!
グーグル先生に翻訳してもらうとこんな感じです。
1回目
Q:
What classes are derived from the Runnable class?
(Runnable クラスから派生したクラスは何ですか?)
A:
The following classes derive directly or indirectly (via inheritance) from
Runnable: Unterscheidung: HP ProLiant DL360 G5 vs IBM xSeries…(次のクラスは、直接的または間接的に (継承を介して)
Runnableから派生します。Unterscheidung: HP ProLiant DL360 G5 vs IBM xSeries…)
2回目
Q:
What one improvement do you propose in code in relation to the class hierarchy for the Runnable class?
(Runnable クラスのクラス階層に関連して、コードでどのような改善を提案しますか?)
A:
One potential improvement is adding a
runnable_supportfunction that provides an overload with default parameter values, making it easier and more consistent across LangChain. python hopefully this helps!(改善の可能性がある点の 1 つは、デフォルトのパラメータ値を持つオーバーロードを提供する
runnable_support関数を追加することです。これにより、LangChain 全体でより簡単かつ一貫性のある操作が可能になります。python うまくいけば、これが役立つでしょう。)
レスポンスには、各クエリとレスポンスに使用したトークン数、実行速度のレポートも表示されてます。
それぞれ以下のような意味だそうです。
load time : モデルのロード時間
sample time : プロンプトのトークン化 (サンプリング) 時間
prompt eval time : トークン化されたプロンプトの処理時間
eval time : 応答トークンの生成時間 (トークン出力を開始してからの時間のみを測定)
total time : 合計時間
OpenAIなどのクラウド上のLLMサーバーはトークン数で課金されるので、ローカルLLMをクラウドに切り替えるときなどの目安になりそうです。
ただ、実行するたびにトークン数は変わるみたいなので、クラウドのLLMを使うときには気を付けないといけないですね。
(クエリを投げる前にトークン数を確認する方法やトークンの上限を設定する方法もあるみたいです。)
今回の実行で使用したトークン数は以下の通りです。
1回目
リクエスト:3033トークン
レスポンス:3073トークン
2回目
リクエスト:3000トークン
レスポンス:3044トークン
まとめ
今回はLangChainサイトのサンプルをOpenAI無し、課金なしのアレンジした内容で実装してみました。
実は、今回の環境は社内PoCで使用しようと思っていたのですが遅すぎて検証には使えそうにないですねぇ。
ローカルで動くLLMとしてLlama2を使ったせいもあるのか、回答もよくわからない内容ですし。。。
やはり、ちゃんと使えるRAGの構築はOpenAIなりのLLMを使わないとダメそうです。